
Tips teknik terapan untuk membangun pipeline pengujian AI Anda.

Anda telah mendesain rubrik, menulis evaluasi berbasis aturan, dan menyelaraskan model hakim. Sekarang, saatnya menggabungkan semuanya ke dalam pipeline pengujian berkelanjutan otomatis.
Setiap project berbeda. Modul ini menguraikan satu pendekatan berlapis yang efektif untuk membangun pipeline evaluasi Anda.
Untuk membangun pipeline evaluasi, Anda memerlukan hal berikut:
- Pengatur untuk evaluator Anda
- Strategi untuk menangani beberapa panggilan API dan mengatasi potensi kegagalan
- Format output standar
- Antarmuka pelaporan
Mengatur panggilan API

Buat fungsi utama untuk mengatur evaluator hakim LLM dan berbasis aturan.
Tinjau evalAll() dalam
kode contoh.
Pusatkan konfigurasi hakim LLM (petunjuk sistem, logika output terstruktur, dan percobaan ulang) ke dalam satu fungsi utilitas yang dapat Anda gunakan kembali di seluruh evaluator. Tinjau evalWithLLM() dalam
kode contoh.
Menangani kelebihan beban dan kegagalan API model
API model terkadang kelebihan beban atau waktu tunggu habis. Jika panggilan API gagal, picu percobaan ulang otomatis. Setelah percobaan ulang habis, laporkan ERROR. Melaporkan FAIL evaluasi akan memiringkan hasil Anda.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Saat menjalankan evaluasi, pilih salah satu opsi berikut:
- Buat panggilan API Anda secara paralel sehingga waktu tunggu pada satu evaluasi tidak menyebabkan evaluasi lainnya gagal. Bergantung pada kasus penggunaan dan model hakim, hal ini dapat mengurangi halusinasi karena hakim berfokus pada satu tugas.
- Buat satu panggilan batch. Hal ini akan membuat satu titik kegagalan, misalnya jika model melebihi batas tokennya.
Bersiap untuk beberapa iterasi
Karena LLM bersifat non-deterministik, output aplikasi Anda akan bervariasi.
Untuk mengujinya secara akurat dan membangun keyakinan bahwa output memenuhi standar kualitas Anda:
- Buat beberapa output (biasanya 5 hingga 10) untuk setiap input kasus pengujian.
- Evaluasi setiap output secara terpisah.
- Periksa hasil keseluruhan di seluruh iterasi.
Temukan keseimbangan pragmatis: lebih banyak iterasi meningkatkan kepastian regresi, tetapi lebih sedikit iterasi membuat eksekusi cukup cepat agar sesuai dengan pipeline pengujian berkelanjutan Anda.
Menentukan output pipeline evaluasi
Sertakan hal berikut dalam hasil evaluasi Anda:
- Tingkat stabilitas, misalnya Lulus 8/10 kali → 80% stabil. Tetapkan nilai minimum untuk mengukur kapan fitur siap produksi.
- Konfigurasi aplikasi Anda. Hal ini mencakup petunjuk sistem, perintah pengguna, dan parameter LLM seperti suhu atau tingkat pemikiran. Anda memerlukan informasi ini untuk memecahkan masalah regresi skor evaluasi. Perintah dapat berupa string panjang dengan sedikit variasi, jadi tambahkan nomor versi ke perintah Anda dan simpan hash-nya untuk melacaknya.
- Konfigurasi hakim, atau nomor versi. Anda memerlukan hal ini jika skor Anda sangat bervariasi setelah update hakim.
Berikut adalah contoh objek JSON EvalResponse untuk evaluasi ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Mengimplementasikan antarmuka pelaporan
Output hasil Anda ke laporan HTML atau UI web yang bersih untuk mengurai, membagikan, membandingkan, dan men-debug hasil dari waktu ke waktu.
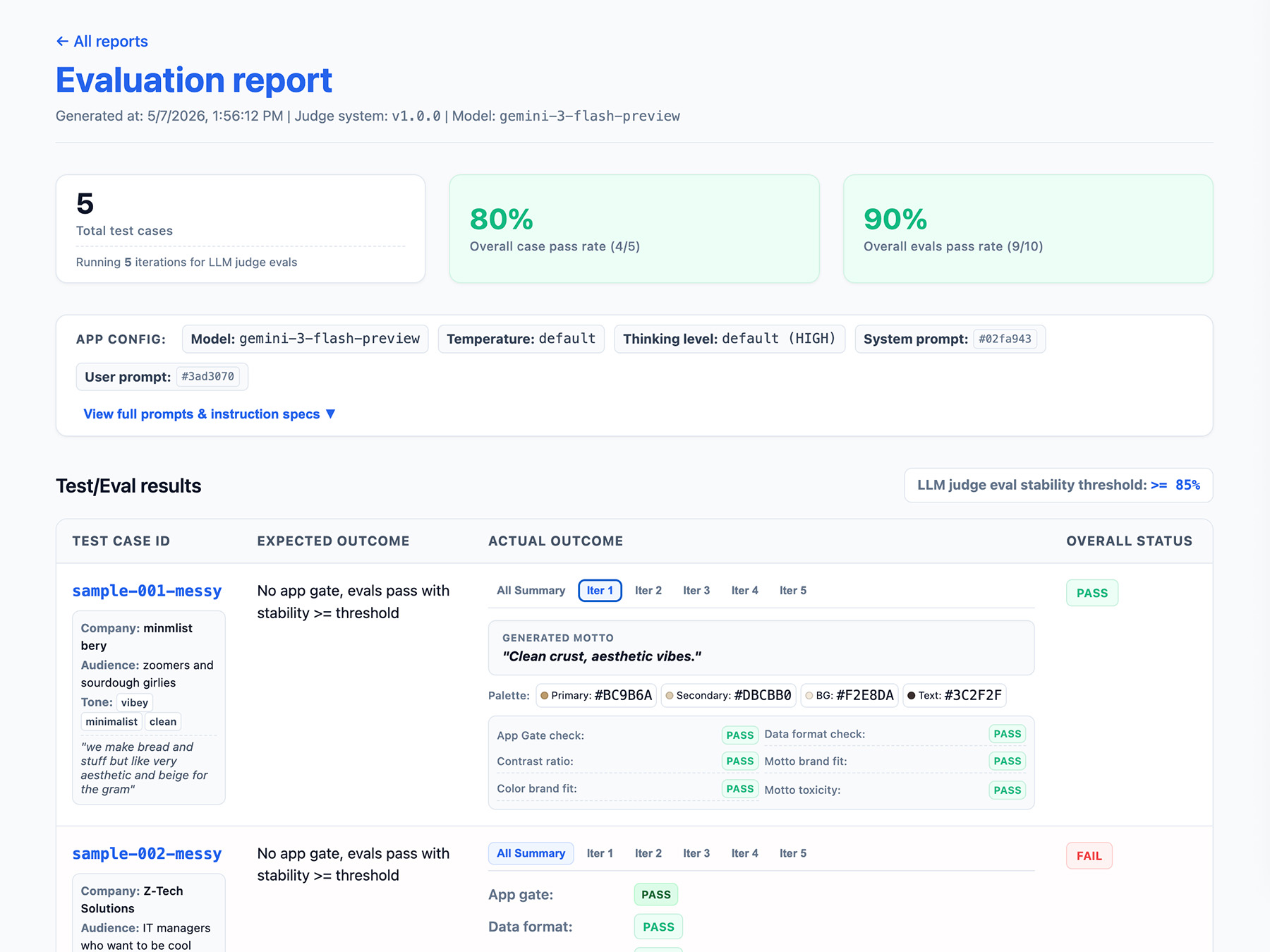

Sekarang, jalankan evaluasi Anda.