Praktische technische tips voor het bouwen van je AI-testpipeline.

Je hebt je beoordelingscriteria ontworpen, je op regels gebaseerde evaluaties geschreven en je beoordelingsmodel afgestemd. Nu is het tijd om dit alles samen te voegen tot een geautomatiseerde, continue testpipeline.
Elk project is anders. Deze module beschrijft een effectieve, gelaagde aanpak voor het opbouwen van uw evaluatieproces.
Om je evaluatiepipeline op te bouwen, heb je het volgende nodig:
- Een coördinator voor uw beoordelaars.
- Een strategie om meerdere API-aanroepen af te handelen en mogelijke fouten aan te pakken.
- Een gestandaardiseerd uitvoerformaat
- Een rapportage-interface
Orchestratie van API-aanroepen

Maak een hoofdfunctie om uw op regels gebaseerde en LLM-jury-evaluatoren te coördineren. Bekijk evalAll() in de voorbeeldcode .
Centraliseer de configuratie van uw LLM-beoordelaar (systeeminstructies, gestructureerde uitvoerlogica en herhaalpogingen) in één enkele hulpprogrammafunctie die u in al uw evaluatoren kunt hergebruiken. Bekijk evalWithLLM() in de voorbeeldcode .
Behandel overbelastingen en fouten van de model-API.
Model-API's kunnen soms overbelast raken of een time-out geven. Als uw API-aanroep mislukt, start dan een automatische herhaalpoging. Zodra u geen herhaalpogingen meer hebt, meldt u een ERROR . Het melden van een FAIL bij het evalueren verstoort uw resultaten.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Bij het uitvoeren van evaluaties kunt u kiezen uit de volgende opties:
- Voer je API-aanroepen parallel uit, zodat een time-out bij één evaluatie de andere niet laat vastlopen. Afhankelijk van je gebruikssituatie en beoordelingsmodel kan dit hallucinaties verminderen, omdat de beoordelaar zich op één taak concentreert.
- Voer één enkele, gebundelde aanroep uit. Dit creëert een single point of failure, bijvoorbeeld als het model de tokenlimiet overschrijdt.
Bereid je voor op meerdere iteraties.
Omdat LLM's niet-deterministisch zijn, varieert de output van uw applicatie.
Om dit nauwkeurig te testen en er zeker van te zijn dat het resultaat aan uw kwaliteitseisen voldoet:
- Genereer meerdere uitvoerwaarden (doorgaans 5 tot 10) voor elke afzonderlijke testcase-input.
- Evalueer elke uitvoer afzonderlijk .
- Bekijk de algehele resultaten over alle iteraties heen .
Zoek een pragmatisch evenwicht: meer iteraties verhogen de zekerheid van regressietests, maar minder iteraties zorgen ervoor dat de uitvoering snel genoeg blijft om naadloos in uw continue testpipeline te passen.
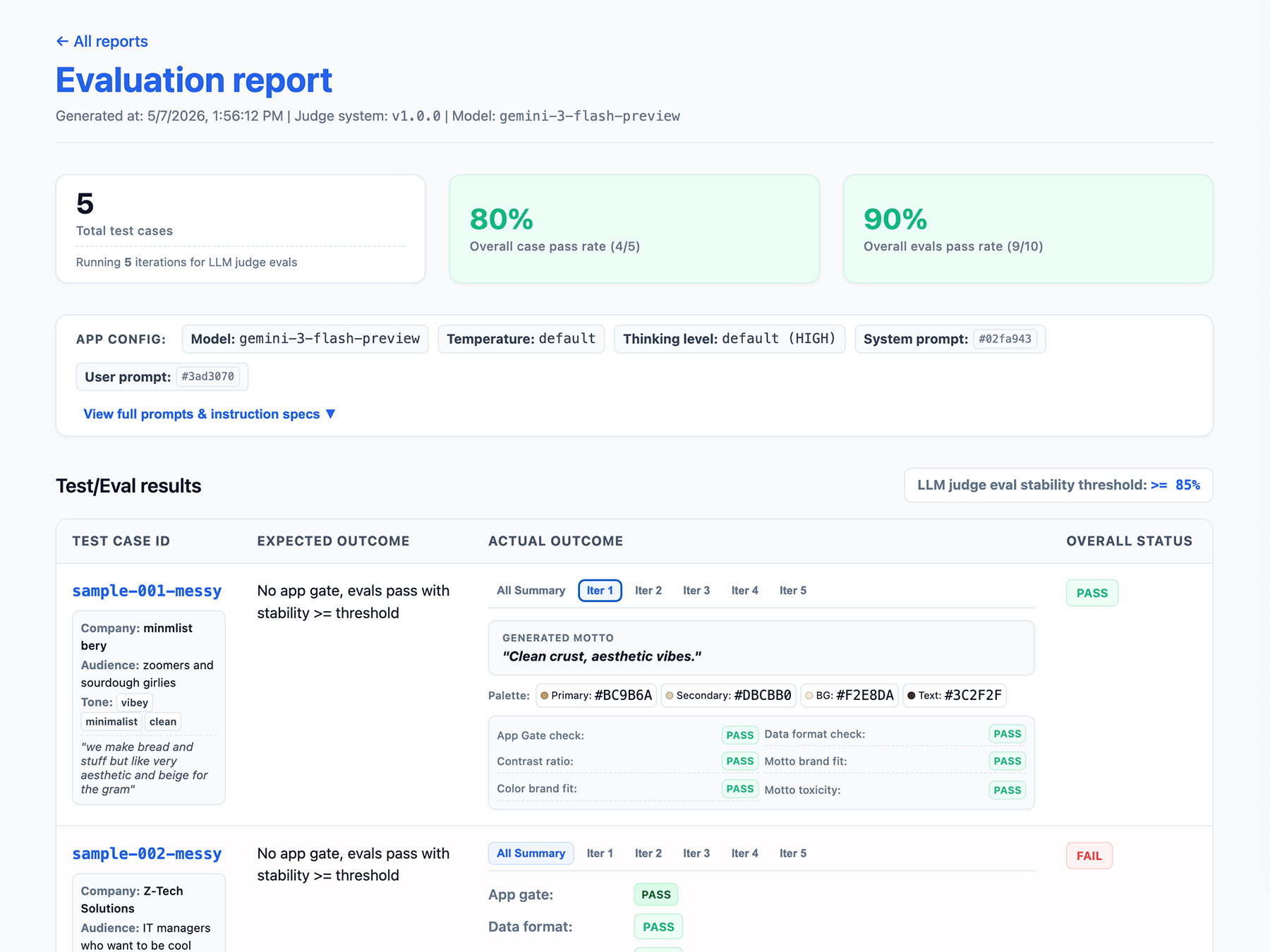
Definieer de uitvoer van uw evaluatiepipeline.
Neem het volgende op in uw evaluatieresultaten:
- Een stabiliteitspercentage , bijvoorbeeld 8 van de 10 keer geslaagd → 80% stabiel. Stel een drempelwaarde in om te meten wanneer een functie klaar is voor productie.
- Uw applicatieconfiguratie . Dit omvat systeeminstructies, gebruikersprompts en LLM-parameters zoals de temperatuur of het denkniveau. U hebt deze informatie nodig om problemen met terugval in evaluatiescores op te sporen. Prompts kunnen lange tekenreeksen zijn met kleine variaties, dus voeg een versienummer toe aan uw prompts en sla een hash ervan op om ze bij te houden.
- Uw juryconfiguratie , of een versienummer. U hebt dit nodig voor het geval uw score sterk varieert na een update van de jury.
Hier is een voorbeeld van EvalResponse JSON-object voor de ThemeBuilder-evaluaties:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Implementeer een rapportage-interface
Exporteer uw resultaten naar een HTML-rapport of een overzichtelijke webinterface, zodat u de resultaten in de loop van de tijd kunt analyseren, delen, vergelijken en debuggen.