

Opublikowano: 1 października 2025 r.
Zanim będzie można używać interfejsów API wbudowanej AI, należy pobrać model bazowy i wszelkie dostosowania (np. dostrajanie), wyodrębnić skompresowane dane i załadować je do pamięci. Zalecaną sprawdzoną metodą jest poinformowanie użytkownika o czasie potrzebnym na pobranie tych plików.
W przykładach poniżej używamy interfejsu Prompt API, ale te same koncepcje można zastosować do wszystkich innych wbudowanych interfejsów API AI.
Monitorowanie i udostępnianie postępu pobierania
Każdy wbudowany interfejs AI API używa funkcji create() do rozpoczęcia sesji. Funkcja
create() ma opcję monitor, dzięki której możesz sprawdzić postęp pobierania i udostępnić go użytkownikowi.
Wbudowane interfejsy API AI są przeznaczone do AI po stronie klienta, gdzie dane są przetwarzane w przeglądarce i na urządzeniu użytkownika, ale niektóre aplikacje mogą umożliwiać przetwarzanie danych na serwerze. Sposób zwracania się do użytkownika w trakcie pobierania modelu zależy od odpowiedzi na pytanie: czy przetwarzanie danych musi odbywać się tylko lokalnie? Jeśli ta wartość to „true”, Twoja aplikacja działa tylko po stronie klienta. W przeciwnym razie aplikacja może korzystać z implementacji hybrydowej.
Tylko po stronie klienta
W niektórych przypadkach wymagane jest przetwarzanie danych po stronie klienta. Na przykład aplikacja medyczna, która umożliwia pacjentom zadawanie pytań dotyczących ich danych osobowych, prawdopodobnie chce, aby te informacje pozostały prywatne na urządzeniu użytkownika. Użytkownik musi poczekać, aż model i wszystkie dostosowania zostaną pobrane i będą gotowe do użycia, zanim będzie mógł korzystać z funkcji przetwarzania danych.
W takim przypadku, jeśli model nie jest jeszcze dostępny, należy wyświetlić użytkownikowi informacje o postępie pobierania.
<style>
progress[hidden] ~ label {
display: none;
}
</style>
<button type="button">Create LanguageModel session</button>
<progress hidden id="progress" value="0"></progress>
<label for="progress">Model download progress</label>
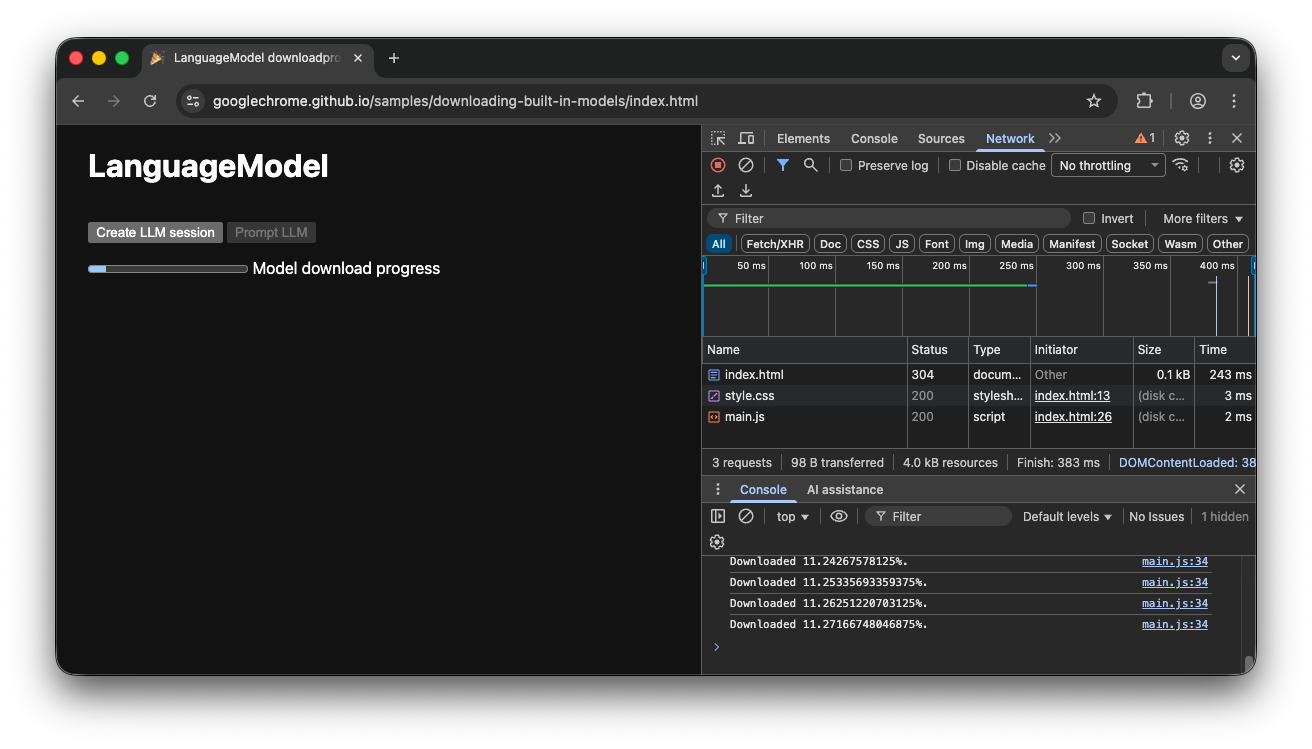
Aby to działało, potrzebny jest JavaScript. Kod najpierw resetuje interfejs postępu do stanu początkowego (postęp ukryty i zerowy), sprawdza, czy interfejs API jest w ogóle obsługiwany, a następnie sprawdza jego dostępność:
- Interfejs API jest
'unavailable': Twojej aplikacji nie można używać po stronie klienta na tym urządzeniu. Powiadom użytkownika, że funkcja jest niedostępna. - Interfejs API jest
'available': można go używać od razu, nie trzeba wyświetlać interfejsu postępu. - Interfejs API jest
'downloadable'lub'downloading': interfejsu API można używać po zakończeniu pobierania. Wyświetlaj wskaźnik postępu i aktualizuj go za każdym razem, gdy zostanie wywołane zdarzeniedownloadprogress. Po pobraniu pokaż stan nieokreślony, aby poinformować użytkownika, że przeglądarka pobiera model i wczytuje go do pamięci.
const createButton = document.querySelector('.create');
const promptButton = document.querySelector('.prompt');
const progress = document.querySelector('progress');
const output = document.querySelector('output');
let sessionCreationTriggered = false;
let localSession = null;
const createSession = async (options = {}) => {
if (sessionCreationTriggered) {
return;
}
progress.hidden = true;
progress.value = 0;
try {
if (!('LanguageModel' in self)) {
throw new Error('LanguageModel is not supported.');
}
const availability = await LanguageModel.availability({
// ⚠️ Always pass the same options to the `availability()` function that
// you use in `prompt()` or `promptStreaming()`. This is critical to
// align model language and modality capabilities.
expectedInputs: [{ type: 'text', languages: ['en'] }],
expectedOutputs: [{ type: 'text', languages: ['en'] }],
});
if (availability === 'unavailable') {
throw new Error('LanguageModel is not available.');
}
let modelNewlyDownloaded = false;
if (availability !== 'available') {
modelNewlyDownloaded = true;
progress.hidden = false;
}
console.log(`LanguageModel is ${availability}.`);
sessionCreationTriggered = true;
const llmSession = await LanguageModel.create({
monitor(m) {
m.addEventListener('downloadprogress', (e) => {
progress.value = e.loaded;
if (modelNewlyDownloaded && e.loaded === 1) {
// The model was newly downloaded and needs to be extracted
// and loaded into memory, so show the undetermined state.
progress.removeAttribute('value');
}
});
},
...options,
});
sessionCreationTriggered = false;
return llmSession;
} catch (error) {
throw error;
} finally {
progress.hidden = true;
progress.value = 0;
}
};
createButton.addEventListener('click', async () => {
try {
localSession = await createSession({
expectedInputs: [{ type: 'text', languages: ['en'] }],
expectedOutputs: [{ type: 'text', languages: ['en'] }],
});
promptButton.disabled = false;
} catch (error) {
output.textContent = error.message;
}
});
promptButton.addEventListener('click', async () => {
output.innerHTML = '';
try {
const stream = localSession.promptStreaming('Write me a poem');
for await (const chunk of stream) {
output.append(chunk);
}
} catch (err) {
output.textContent = err.message;
}
});
Jeśli użytkownik otworzy aplikację, gdy model jest aktywnie pobierany do przeglądarki, interfejs postępu wskaże, na jakim etapie jest pobieranie, na podstawie danych still missing.
Wersja demonstracyjna po stronie klienta
Obejrzyj prezentację, która pokazuje ten proces w praktyce. Jeśli wbudowany interfejs API AI (w tym przykładzie interfejs Prompt API) nie jest dostępny, nie można używać aplikacji. Jeśli wbudowany model AI nadal wymaga pobrania, użytkownikowi wyświetla się wskaźnik postępu. Kod źródłowy możesz zobaczyć na GitHubie.
Implementacja hybrydowa
Jeśli wolisz korzystać z AI po stronie klienta, ale możesz tymczasowo wysyłać dane do chmury, możesz skonfigurować wdrożenie hybrydowe. Oznacza to, że użytkownicy mogą od razu korzystać z funkcji, a w tym samym czasie pobierać model lokalny. Po pobraniu modelu dynamicznie przełącz się na sesję lokalną.
W przypadku implementacji hybrydowej możesz użyć dowolnej implementacji po stronie serwera, ale prawdopodobnie najlepiej będzie używać tej samej rodziny modeli w chmurze i lokalnie, aby uzyskać porównywalną jakość wyników. Wprowadzenie do interfejsu Gemini API i aplikacji internetowych zawiera omówienie różnych podejść do interfejsu Gemini API.
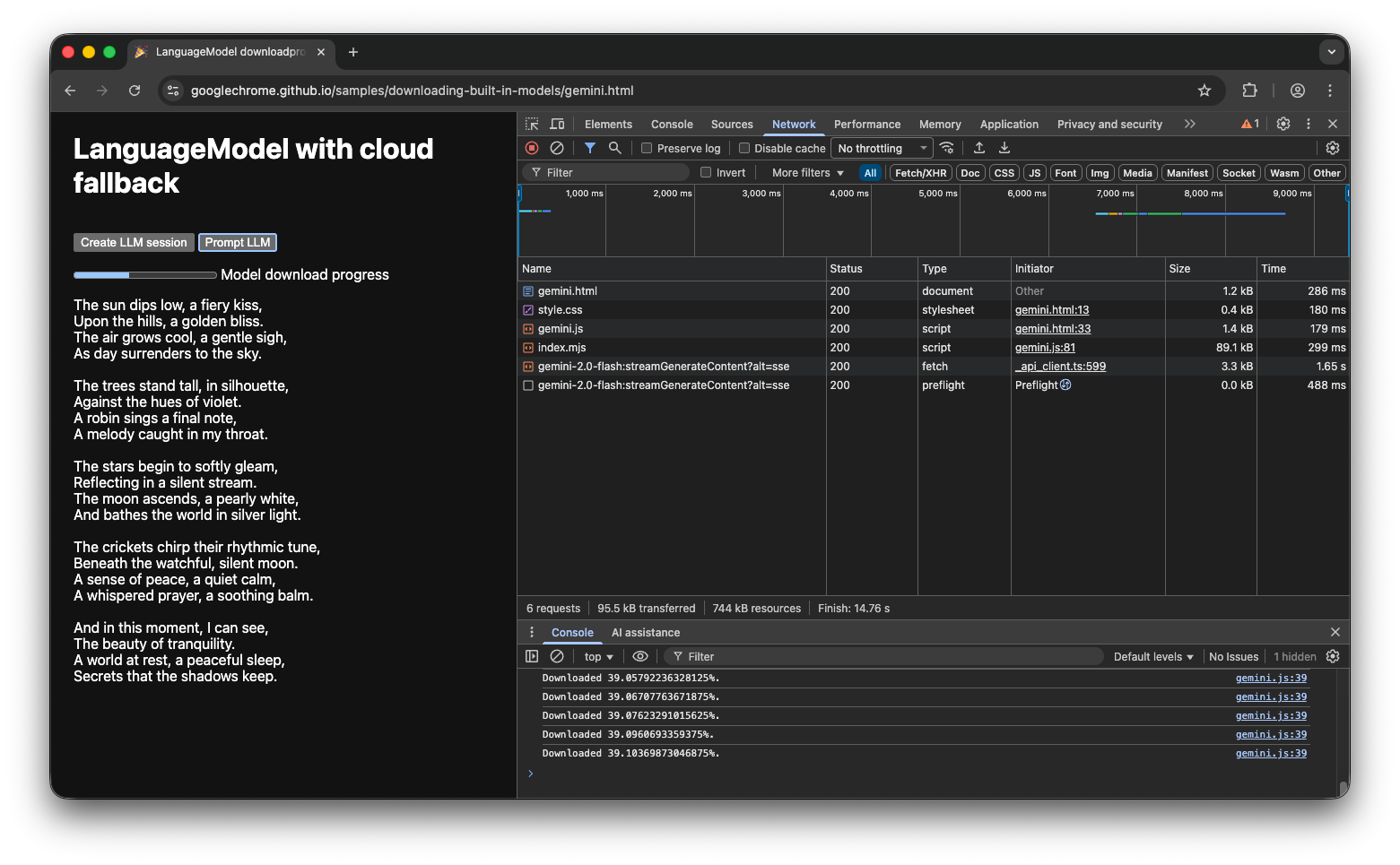
Wersja demonstracyjna hybrydowa
W wersji demonstracyjnej możesz zobaczyć, jak to działa. Jeśli wbudowany interfejs AI API jest niedostępny, wersja demonstracyjna przełącza się na interfejs Gemini API w chmurze. Jeśli wbudowany model nadal wymaga pobrania, użytkownikowi wyświetla się wskaźnik postępu, a aplikacja korzysta z interfejsu Gemini API w chmurze do momentu pobrania modelu. Zapoznaj się z pełnym kodem źródłowym na GitHubie.
Podsumowanie
Do jakiej kategorii należy Twoja aplikacja? Czy potrzebujesz przetwarzania w 100% po stronie klienta, czy możesz zastosować podejście hybrydowe? Po udzieleniu odpowiedzi na to pytanie musisz wdrożyć strategię pobierania modelu, która najlepiej Ci odpowiada.
Zadbaj o to, aby użytkownicy zawsze wiedzieli, kiedy i czy mogą już korzystać z aplikacji po stronie klienta. W tym celu pokazuj im postęp pobierania modelu zgodnie z instrukcjami w tym przewodniku.
Pamiętaj, że to nie jest jednorazowe wyzwanie: jeśli przeglądarka usunie model z powodu braku miejsca na dane lub gdy będzie dostępna nowa wersja modelu, będzie musiała pobrać go ponownie. Niezależnie od tego, czy zastosujesz podejście po stronie klienta, czy hybrydowe, możesz mieć pewność, że zapewnisz użytkownikom najlepsze możliwe wrażenia, a reszta będzie po stronie przeglądarki.