

เผยแพร่เมื่อ: 30 เมษายน 2026
ด้วย AI ในตัว เว็บไซต์หรือเว็บแอปพลิเคชันของคุณจึงสามารถทำงานที่ขับเคลื่อนด้วย AI ได้โดยไม่จำเป็นต้องทำให้ใช้งานได้ จัดการ หรือโฮสต์โมเดลด้วยตนเอง คุณอาจพบว่าการย้ายจากเดโมไปยังฟีเจอร์ที่พร้อมใช้งานจริงเป็นเรื่องท้าทาย เอกสารนี้ครอบคลุมข้อควรพิจารณาด้านเทคนิคและ UX เพื่อช่วยคุณหลีกเลี่ยงข้อผิดพลาดที่พบบ่อย
เตรียมโมเดลในเวลาที่เหมาะสม
ใช้ได้กับ API ทั้งหมด เช่น Summarizer, Translator และ Writer
ควร: เริ่มต้นเซสชันทันทีที่คุณทราบเจตนาของผู้ใช้ที่จะใช้ฟีเจอร์ AI อย่างชัดเจน เช่น เมื่อผู้ใช้ไปยังส่วนต่างๆ ของเครื่องมือ AI ที่เกี่ยวข้อง วางเมาส์เหนือพื้นที่ทำงาน AI หรือโต้ตอบกับ UI โดยรอบของฟีเจอร์ การเตรียมเซสชันล่วงหน้าจะช่วยให้โมเดลโหลดลงในหน่วยความจำอย่างเงียบๆ ในเบื้องหลังขณะที่ผู้ใช้กำลังตั้งค่างาน ซึ่งจะช่วยลดเวลาในการเริ่มต้นระบบที่หลีกเลี่ยงได้ พยายามนำหน้าไป 1 ก้าวโดยเริ่มงาน AI ที่มีแนวโน้มมากที่สุดถัดไปทันทีที่คุณเริ่มแสดงผลลัพธ์ปัจจุบัน เช่น หากฟีเจอร์ได้รับการออกแบบมาให้ใช้ซ้ำๆ
ไม่ควร: เว้นแต่จำเป็น อย่ารอให้ผู้ใช้คลิก "สร้าง" เพื่อเริ่มต้นเซสชัน ซึ่งจะทำให้เกิดความล่าช้าในการเริ่มต้นระบบ เนื่องจากโมเดลต้องโหลดลงในหน่วยความจำและเตรียมไปป์ไลน์การดำเนินการก่อน
ตั้งค่าพรอมต์เริ่มต้นระหว่างการสร้าง
ใช้ได้กับ Prompt API
ควร: ให้คำแนะนำระบบระหว่างการเริ่มต้นเซสชันเพื่อเพิ่มความเร็วของพรอมต์แรก
ไม่ควร: เริ่มต้นด้วยเซสชันว่างเปล่าและส่งคำแนะนำระบบเป็นส่วนหนึ่งของ
การเรียก prompt() ครั้งแรก ซึ่งจะเพิ่มความหน่วงเนื่องจากบังคับให้โมเดลประมวลผลคำแนะนำเหล่านั้นในนาทีสุดท้าย
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
โคลนเซสชันสำหรับงานที่ทำซ้ำ
ใช้ได้กับ Prompt API
สำหรับ Prompt API แต่ละเซสชันจะ ติดตามบริบทของ การสนทนา โดยคำนึงถึงการโต้ตอบก่อนหน้านี้ทั้งหมด เนื่องจากโคลนจะรับทุกอย่างจากเซสชันหลัก รวมถึงพรอมต์เริ่มต้นและประวัติการโต้ตอบทั้งหมดจนถึงจุดที่โคลน ให้จัดโครงสร้างการใช้งานเพื่อรับเฉพาะสิ่งที่คุณต้องการ
ควร
- สร้างเซสชันฐาน: สร้างเซสชันฐานที่มีเฉพาะคำแนะนำระบบและไม่มีบริบทการสนทนาก่อนหน้า เพื่อจัดการงานที่ไม่เกี่ยวข้องอย่างมีประสิทธิภาพ
- โคลนบรรทัดฐาน: ใช้
clone()ในเซสชันฐานนั้นสำหรับงานใหม่เพื่อประหยัดค่าใช้จ่ายในการแยกวิเคราะห์คำแนะนำระบบอีกครั้ง ซึ่งจะช่วยให้คุณสร้างการสนทนาแบบขนานหรือรีเซ็ตงานเป็นบรรทัดฐานได้
ไม่ควร:
- อย่าใช้เซสชันเดียวกันซ้ำสำหรับงานที่ไม่เกี่ยวข้อง และหลีกเลี่ยงการโคลนเซสชันที่มีประวัติการโต้ตอบที่ไม่จำเป็นอยู่แล้ว รูปแบบทั้ง 2 แบบอาจทำให้บริบทก่อนหน้าที่ไม่เกี่ยวข้องรบกวนงานปัจจุบัน
- อย่าเรียก
create()ซ้ำๆ ด้วยคำแนะนำระบบที่เหมือนกัน ให้ใช้รูปแบบการโคลนแทนเพื่อเพิ่มประสิทธิภาพ
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
ทำลายเซสชันที่ไม่ได้ใช้
ใช้ได้กับ API ทั้งหมด
ควร: เรียก destroy() อย่างชัดเจนใน
เซสชันที่คุณไม่ต้องการอีกต่อไป เพื่อเพิ่มพื้นที่หน่วยความจำเมื่อไม่ได้ใช้ฟีเจอร์
หากใช้รูปแบบการโคลน ให้เก็บเซสชันฐานไว้และทำลายโคลนที่คุณไม่ต้องการอีกต่อไป
ไม่ควร: เปิดใช้งานเซสชันขนาดใหญ่หลายรายการ เนื่องจากแต่ละเซสชันใช้หน่วยความจำ ซึ่งทำให้เกิดการใช้ทรัพยากรโดยไม่จำเป็นและอาจกลายเป็นปัญหาได้ ระบบจะล้างเซสชันโดยตัวเก็บขยะโดยอัตโนมัติ แต่การเรียก destroy() จะเพิ่มพื้นที่หน่วยความจำได้เร็วกว่า
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
แสดงผลการตอบกลับแบบสตรีมมิงอย่างปลอดภัยและมีประสิทธิภาพ
ใช้ได้กับ API ทั้งหมดที่รองรับการสตรีมมิง (Prompt, Summarizer, Writer, Rewriter และ Translator)
ควร: ถือว่าเอาต์พุต LLM ทั้งหมดเป็นเนื้อหาที่ไม่น่าเชื่อถือ ล้างข้อมูลเอาต์พุตที่รวมกันทั้งหมด ไม่ใช่แค่ Chunk เนื่องจากโค้ดที่เป็นอันตรายอาจแยกออกจากการอัปเดต ก่อนแสดงผล ให้ใช้ Sanitizer API ในกรณีที่ รองรับ ใช้ตัวแยกวิเคราะห์ Markdown แบบสตรีมมิง เช่น streaming-markdown เพื่อหลีกเลี่ยงประสิทธิภาพที่ลดลง
ไม่ควร: ตั้งค่า innerHTML โดยตรงในการอัปเดต Chunk ทุกครั้ง เนื่องจากวิธีนี้ช้า โดยเฉพาะอย่างยิ่งกับการจัดรูปแบบที่ซับซ้อน เช่น การไฮไลต์ไวยากรณ์ และเสี่ยงต่อการแทรก
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
เพิ่มประสิทธิภาพอินพุตเพื่อความเร็ว
ใช้ได้กับ API ทั้งหมด
ควร: ส่งเฉพาะสิ่งที่จำเป็นอย่างยิ่งไปยังโมเดล นำทุกอย่างที่ไม่เกี่ยวข้องกับงานที่ทำออก สำหรับชุดข้อมูลขนาดใหญ่ ให้ระบุภาพรวมสั้นๆ และเลือกรายการที่เกี่ยวข้องเพียงเล็กน้อย
ไม่ควร: ส่งข้อความดิบที่ยังไม่ได้ประมวลผล ข้อมูลเมตาที่ไม่จำเป็น แท็ก HTML หรือรายการขนาดใหญ่ ที่ไม่ได้กรองไปยัง API ความหน่วงจะเพิ่มขึ้นอย่างมากตามขนาดอินพุต ซึ่งอาจทำให้ฟีเจอร์ AI ดูเหมือนใช้งานไม่ได้ในอุปกรณ์หลายเครื่อง
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
ใช้เอาต์พุตที่มีโครงสร้างเพื่อให้ได้ผลลัพธ์ที่คาดการณ์ได้
ใช้ได้กับ Prompt API
ควร: เมื่อต้องการให้โมเดลแสดงผลข้อมูลในรูปแบบที่เฉพาะเจาะจง ให้ใช้
เอาต์พุตที่มีโครงสร้าง
โดยระบุช่อง responseConstraint เพื่อระบุ JSON Schema ซึ่งจะช่วยให้เอาต์พุตคาดการณ์ได้และป้องกันไม่ให้คุณต้องทำการประมวลผลภายหลังที่ซับซ้อนหรือแยกวิเคราะห์ด้วยตนเอง
ไม่ควร: อาศัยคำแนะนำภาษาธรรมชาติ (เช่น "แสดงผลเฉพาะ JSON") เพียงอย่างเดียว เนื่องจากโมเดลอาจรวมคำเติมในการสนทนาที่ทำให้ตัวแยกวิเคราะห์ของคุณใช้งานไม่ได้
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
แยกการสร้างออกจากข้อจำกัดด้านความยาว
ใช้ได้กับ Prompt API เนื่องจากเป็น API เดียวที่รองรับสคีมาเอาต์พุตที่มีโครงสร้าง
ควร: ให้โมเดลสร้างการตอบกลับตามธรรมชาติ แล้วใช้ตรรกะฝั่งไคลเอ็นต์เพื่อตัดข้อความให้พอดีกับ UI
ไม่ควร: บังคับใช้ขีดจำกัดอักขระที่เข้มงวด เช่น maxLength: 125 โดยใช้
สคีมาเอาต์พุตที่มีโครงสร้าง เมื่อการตอบกลับของโมเดลยาวกว่าขีดจำกัดที่คุณตั้งไว้ โมเดลอาจเปลี่ยนไปใช้โทเค็นความหนาแน่นสูง เช่น ภาษาต่างประเทศหรืออิโมจิ เพื่อบีบอัดความหมาย ซึ่งส่งผลให้เอาต์พุตไม่มีความหมาย
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
แจ้งให้ผู้ใช้ทราบ
ใช้ได้กับ API ทั้งหมด
ควร: ใช้ภาพเคลื่อนไหว สัญญาณภาพ และตัวบ่งชี้ความคืบหน้าเพื่อแจ้งให้ผู้ใช้ทราบ ทั้งนี้ขึ้นอยู่กับความซับซ้อนและระยะเวลาที่คาดไว้ของงาน แนวทางที่ดีที่สุดจะขึ้นอยู่กับกรณีการใช้งานและความยาวที่คาดไว้ของเอาต์พุต API ลองดูไอเดียต่อไปนี้เป็นตัวอย่าง
- การสตรีมมิงสำหรับเนื้อหายาว: สำหรับสรุปหรือแชท การสตรีมมิงจะสร้างเอฟเฟกต์เครื่องพิมพ์ดีดต่อโทเค็นโดยค่าเริ่มต้น ซึ่งอาจดูเป็นธรรมชาติและให้ความคิดเห็นได้ทันที
- การไม่สตรีมมิงสำหรับงานสั้นๆ (หรืองานแบบไม่พร้อมกันที่ใช้เวลานาน): สำหรับเอาต์พุตสั้นๆ เช่น ข้อความแสดงแทน การไม่สตรีมมิงอาจสร้าง UI ที่สวยงามยิ่งขึ้น นอกจากนี้ยังช่วยให้มีเวลาเตรียมงาน AI ถัดไปแบบคาดการณ์ไว้ขณะที่งานปัจจุบันกำลังแสดงผล แนวทางนี้ยังใช้ได้กับงานแบบไม่พร้อมกันหรืองานเบื้องหลังที่ใช้เวลานานขึ้น หากผู้ใช้ไม่ถูกบล็อกเอาต์พุตเพื่อดำเนินการต่อ ก็ไม่จำเป็นต้องสร้างเอาต์พุตทันทีที่เกิดเหตุการณ์ ให้ส่งสัญญาณว่ากระบวนการกำลังดำเนินอยู่ภายใน UI
- การเปลี่ยนภาพสำหรับการอัปเดต: เมื่อแปลหรือเขียนข้อความใหม่ ให้ใช้ภาพเคลื่อนไหว เช่น การเปลี่ยนรูปร่างของคำ
ไม่ควร: อัปเดต UI โดยไม่มีสัญญาณภาพ
สอดคล้องกับโมเดลความคิดของผู้ใช้เกี่ยวกับเวลาและการทำงาน
ใช้ได้กับ API ทั้งหมด
ควร: พิจารณาการหน่วงเวลาเทียม 1 หรือ 2 วินาทีหากการตอบกลับเกิดขึ้นเกือบจะทันที ผู้ใช้อาจเชื่อถือผลลัพธ์มากขึ้นอย่างน่าประหลาดใจเมื่อรับรู้ถึงกระบวนการสร้างที่สอดคล้องกับความยากของงานที่ตนรับรู้ ใช้ภาพเคลื่อนไหวเพื่อส่งสัญญาณว่ากระบวนการ AI เกิดขึ้นแล้ว
ไม่ควร: ทำให้ผู้ใช้ประหลาดใจด้วยการแทนที่ UI ทันที
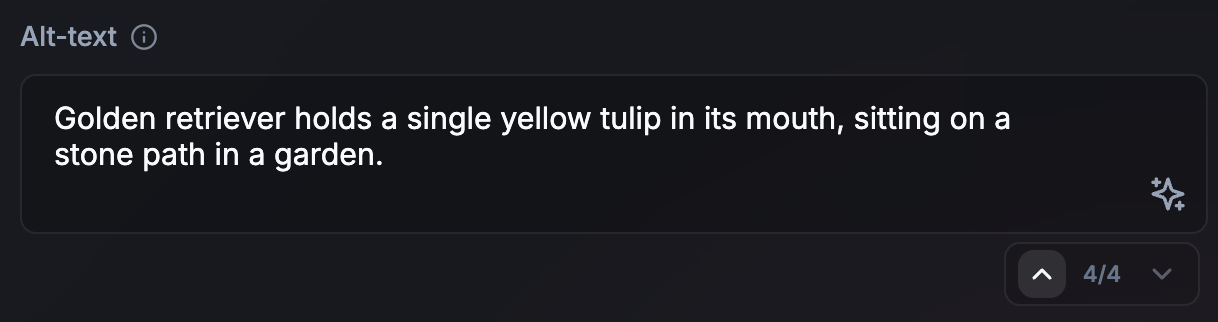
อนุญาตให้ผู้ใช้ไปยังส่วนต่างๆ และเลิกทำการแก้ไข AI ได้อย่างรวดเร็ว
ใช้ได้กับ API ทั้งหมด
ควร: ติดตั้ง UI ด้วยตัวควบคุมแบบขั้นบันไดหรือประวัติการไปยังส่วนต่างๆ ที่ช่วยให้ผู้ใช้สำรวจผลลัพธ์ต่างๆ ได้อย่างมั่นใจ และอนุญาตให้เลิกทำการแก้ไข AI ได้อย่างรวดเร็ว ซึ่งจะช่วยให้มั่นใจว่าเวอร์ชันต่างๆ ยังคงพร้อมใช้งาน
ไม่ควร: เขียนทับฉบับร่างก่อนหน้าของผู้ใช้หรือผลลัพธ์ AI ที่ผู้ใช้อาจ ชอบโดยไม่มีวิธีกลับไป เปรียบเทียบ หรือเปรียบเทียบเวอร์ชัน
เพิ่มขีดความสามารถในการควบคุมและการลบล้างของผู้ใช้
ใช้ได้กับ API ทั้งหมด
ควร: กำหนดให้ผู้ใช้เป็นเอดิเตอร์สุดท้ายของเนื้อหาที่สร้างขึ้นทั้งหมด ระบุการลบล้างที่ใช้งานง่ายเพื่อให้ผู้ใช้ยังคงเป็นเจ้าของเอาต์พุตสุดท้ายอย่างเต็มรูปแบบ เนื่องจาก API อาจแสดงผลลัพธ์ที่ไม่ถูกต้อง
ไม่ควร: บังคับให้ผลลัพธ์ที่สร้างโดย AI เป็นตัวเลือกเดียว
แคชผลลัพธ์สำหรับงานที่ทำซ้ำ
ใช้ได้กับ API ทั้งหมด
ควร: ใช้แคชผลลัพธ์ในเครื่อง (เช่น ใช้ sessionStorage หรือ IndexedDB) สำหรับอินพุตหรือการค้นหาที่ทำซ้ำ ทำให้อินพุตเป็นมาตรฐานโดยการตัดช่องว่างและเปลี่ยนเป็นตัวพิมพ์เล็กเพื่อเพิ่มจำนวนการเข้าถึงแคช สำหรับอินพุตขนาดใหญ่ เช่น รูปภาพ ให้สร้างแฮชเพื่อใช้เป็นคีย์แคช ตั้งค่า Time to Live (TTL) ที่ระมัดระวังสำหรับแคช (หรือแสดงผลลัพธ์ที่แคชไว้ขณะอัปเดตในเบื้องหลัง) อนุญาตให้ผู้ใช้ทริกเกอร์การอนุมานใหม่หากผลลัพธ์ไม่เป็นที่น่าพอใจ
ไม่ควร: เรียกใช้การอนุมานเดียวกันซ้ำสำหรับการค้นหาที่ทำซ้ำหรืออินพุตข้อมูลที่เหมือนกันซึ่งไม่ต้องการความแปรปรวน เช่น เมื่อผู้ใช้ไปยังส่วนต่างๆ ของผลการค้นหา ซึ่งจะเพิ่มประสิทธิภาพการตอบสนองและการใช้การคำนวณในเครื่องอย่างมีประสิทธิภาพ
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}