
AI 테스트 파이프라인을 빌드하기 위한 엔지니어링 팁을 적용하세요.

루브릭을 설계하고, 규칙 기반 평가를 작성하고, 심사자 모델을 정렬했습니다. 이제 이 모든 것을 자동화된 지속적 테스트 파이프라인으로 연결할 차례입니다.
프로젝트마다 다릅니다. 이 모듈에서는 평가 파이프라인을 구축하는 효과적인 계층화된 접근 방식을 설명합니다.
평가 파이프라인을 빌드하려면 다음이 필요합니다.
- 평가자를 위한 오케스트레이터
- 여러 API 호출을 처리하고 잠재적 실패를 해결하는 전략
- 표준화된 출력 형식
- 보고 인터페이스
API 호출 오케스트레이션

규칙 기반 평가자와 LLM 평가자를 오케스트레이션하는 기본 함수를 만듭니다.
예시 코드에서 evalAll()를 검토합니다.
LLM 심사관 구성 (시스템 안내, 구조화된 출력 로직, 재시도)을 평가자 전반에서 재사용할 수 있는 단일 유틸리티 함수로 중앙 집중화합니다. 예시 코드에서 evalWithLLM()를 검토합니다.
모델 API 오버로드 및 실패 처리
모델 API가 과부하되거나 시간이 초과되는 경우가 있습니다. API 호출이 실패하면 자동 재시도를 트리거합니다. 재시도 횟수가 소진되면 ERROR를 보고합니다. 평가 FAIL를 보고하면 결과가 왜곡됩니다.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
평가를 실행할 때 다음 옵션 중에서 선택하세요.
- 하나의 평가에서 타임아웃이 발생해도 다른 평가가 비정상 종료되지 않도록 병렬로 API를 호출하세요. 사용 사례와 심판 모델에 따라 심판이 한 가지 작업에 집중하므로 환각 현상이 줄어들 수 있습니다.
- 단일 일괄 호출을 실행합니다. 이렇게 하면 모델이 토큰 한도를 초과하는 경우와 같은 단일 장애점이 발생합니다.
여러 번의 반복 준비
LLM은 비결정적이므로 애플리케이션 출력이 달라집니다.
이를 정확하게 테스트하고 출력이 품질 기준을 충족한다는 확신을 얻으려면 다음 단계를 따르세요.
- 모든 단일 테스트 사례 입력에 대해 여러 출력 (일반적으로 5~10개)을 생성합니다.
- 각 출력을 별도로 평가합니다.
- 반복 전반의 전체 결과를 살펴봅니다.
실용적인 균형을 찾으세요. 반복 횟수가 많을수록 회귀 확실성이 높아지지만 반복 횟수가 적을수록 지속적 테스트 파이프라인에 원활하게 맞출 수 있을 만큼 실행 속도가 빨라집니다.
평가 파이프라인 출력 정의
평가 결과에 다음을 포함하세요.
- 안정성 비율(예: 10번 중 8번 통과 → 안정성 80%) 기능이 프로덕션 준비가 되었는지 측정하는 기준을 설정합니다.
- 애플리케이션 구성 여기에는 시스템 요청 사항, 사용자 프롬프트, 온도 또는 사고 수준과 같은 LLM 파라미터가 포함됩니다. 평가 점수 회귀 문제를 해결하려면 이 정보가 필요합니다. 프롬프트는 약간의 변형이 있는 긴 문자열일 수 있으므로 프롬프트에 버전 번호를 추가하고 해시를 저장하여 추적하세요.
- 평가 구성 또는 버전 번호 심사위원 업데이트 후 점수가 크게 달라지는 경우에 필요합니다.
ThemeBuilder 평가를 위한 EvalResponse JSON 객체의 예는 다음과 같습니다.
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
보고 인터페이스 구현
결과를 HTML 보고서 또는 깨끗한 웹 UI로 출력하여 시간이 지남에 따라 결과를 파싱, 공유, 비교, 디버그합니다.
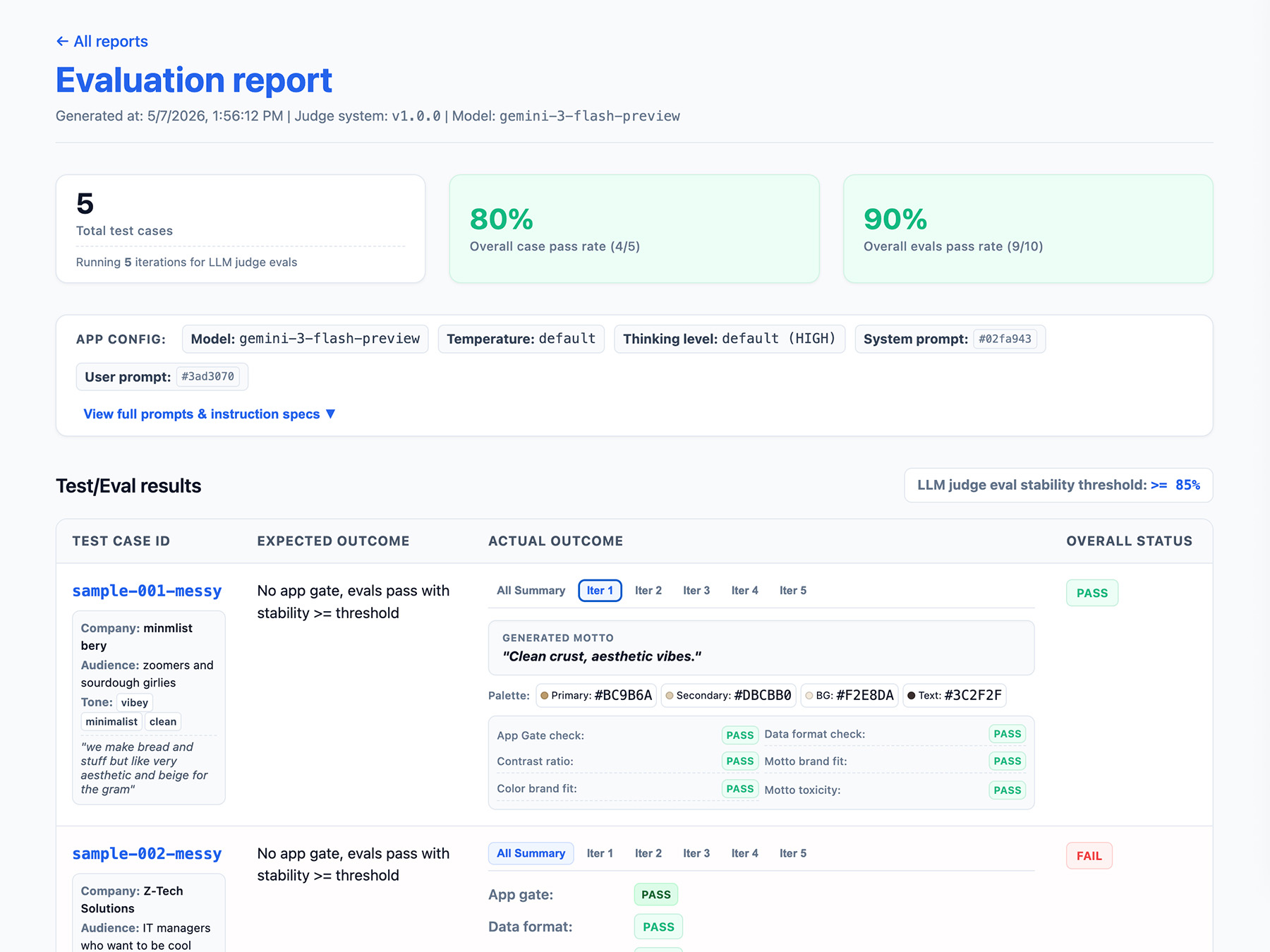

이제 평가를 실행합니다.