

Gepubliceerd: 30 april 2026
Met ingebouwde AI kan uw website of webapplicatie AI-gestuurde taken uitvoeren zonder dat u modellen hoeft te implementeren, beheren of zelf te hosten. De overgang van een demo naar een productierijpe functionaliteit kan een uitdaging zijn. Dit document behandelt technische en UX-overwegingen om u te helpen veelvoorkomende valkuilen te vermijden.
Bereid het model voor op een redelijk tijdstip.
Van toepassing op: alle API's, bijvoorbeeld Summarizer, Translator en Writer.
Doe: Initialiseer de sessie zodra duidelijk is dat de gebruiker de AI-functie wil gebruiken, bijvoorbeeld wanneer een gebruiker naar een relevant AI-tools-scherm navigeert, met de muis over een AI-werkruimte beweegt of interactie heeft met de gebruikersinterface van de functie. Door de sessie vooraf te starten, kan het model op de achtergrond stil in het geheugen worden geladen terwijl de gebruiker zijn taak instelt, waardoor onnodige opstartvertraging wordt voorkomen. Probeer een stap voor te zijn door de volgende meest waarschijnlijke AI-taak te starten zodra u begint met het renderen van het huidige resultaat, bijvoorbeeld als de functie is ontworpen voor iteratief gebruik.
Niet doen: Wacht, tenzij noodzakelijk, niet tot de gebruiker op 'Genereren' klikt om de sessie te initialiseren. Dit leidt tot een opstartvertraging, omdat het model eerst in het geheugen moet worden geladen en de uitvoeringspipeline moet worden voorbereid.
Stel de beginprompts in tijdens het aanmaken.
Van toepassing op: Prompt API.
Doe: Geef systeeminstructies tijdens de sessie-initialisatie om de snelheid van de eerste prompt te verbeteren.
Niet doen: Begin met een lege sessie en verstuur systeeminstructies als onderdeel van de eerste prompt() aanroep. Dit verhoogt de latentie omdat het model die instructies op het allerlaatste moment moet verwerken.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
Kloon sessies voor repetitieve taken
Van toepassing op: Prompt API.
Voor de Prompt API houdt elke sessie de context van het gesprek bij , waarbij alle eerdere interacties in aanmerking worden genomen. Omdat een kloon alles van de oudersessie overneemt, inclusief de initiële prompts en alle interactiegeschiedenis tot het moment van klonen, is het raadzaam om uw gebruik zo in te richten dat u alleen overneemt wat u nodig hebt.
Doen:
- Een basissessie aanmaken: Om taken die niets met elkaar te maken hebben efficiënt af te handelen, maakt u een basissessie aan die alleen uw systeeminstructies bevat en geen eerdere gesprekscontext.
- Kloon de basislijn: Gebruik
clone()op die basissessie voor nieuwe taken om de overhead van het opnieuw parsen van systeeminstructies te besparen. Hiermee kunt u parallelle gesprekken creëren of een taak terugzetten naar de basislijn.
Niet doen:
- Gebruik dezelfde sessie niet opnieuw voor taken die er niets mee te maken hebben, en vermijd het klonen van sessies die al onnodige interactiegeschiedenis bevatten. Beide werkwijzen kunnen ervoor zorgen dat irrelevante eerdere context uw huidige taak verstoort.
- Roep de functie
create()niet herhaaldelijk aan met identieke systeeminstructies. Gebruik in plaats daarvan het kloonpatroon om de prestaties te optimaliseren.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
Verwijder ongebruikte sessies
Van toepassing op: Alle API's.
Doe het volgende: Roep expliciet de destroy() -methode aan voor sessies die je niet langer nodig hebt, om geheugen vrij te maken wanneer een functie niet meer in gebruik is. Als je een kloonpatroon gebruikt, behoud dan de basissessie en verwijder de klonen die je niet langer nodig hebt.
Niet doen: Meerdere grote sessies tegelijk actief houden. Elke sessie verbruikt geheugen, wat leidt tot onnodig resourcegebruik en mogelijk problemen kan veroorzaken. Sessies worden vanzelf opgeruimd door de garbage collector, maar door destroy() aan te roepen, wordt geheugen sneller vrijgemaakt.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
Verwerk streamingreacties veilig en efficiënt.
Van toepassing op: Alle API's met streamingondersteuning (Prompt, Summarizer, Writer, Rewriter en Translator).
Doe: Behandel alle LLM-uitvoer als onbetrouwbare inhoud. Saniteer de volledige gecombineerde uitvoer, niet alleen delen ervan, omdat kwaadaardige code verspreid kan zijn over verschillende updates. Gebruik de Sanitizer API vóór het renderen, indien ondersteund. Gebruik een streaming Markdown-parser zoals streaming-markdown om prestatieverlies te voorkomen.
Niet doen: innerHTML direct instellen bij elke chunk-update. Dit is traag, vooral bij complexe opmaak zoals syntax highlighting, en kwetsbaar voor injectieaanvallen.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
Optimaliseer de invoer voor snelheid.
Van toepassing op: Alle API's.
Doe: Geef alleen de strikt noodzakelijke informatie door aan het model. Verwijder alles wat irrelevant is voor de taak. Geef bij grote datasets een kort overzicht en een kleine selectie van relevante items.
Niet doen: Stuur geen onbewerkte tekst, onnodige metadata, HTML-tags of grote, ongefilterde lijsten naar de API's. De latentie neemt aanzienlijk toe met de grootte van de invoer, waardoor de AI-functie op veel apparaten mogelijk niet goed werkt.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
Gebruik gestructureerde uitvoer voor voorspelbare resultaten.
Van toepassing op: Prompt API.
Doe: Wanneer je wilt dat het model gegevens in een specifiek formaat retourneert, gebruik dan gestructureerde uitvoer door een responseConstraint veld op te geven met een JSON-schema. Dit zorgt ervoor dat de uitvoer voorspelbaar is en voorkomt dat je complexe nabewerking of handmatige parsing nodig hebt.
Niet doen: Vertrouw uitsluitend op instructies in natuurlijke taal (zoals "alleen JSON uitvoeren"). Modellen kunnen namelijk opvulling bevatten die je parser kan laten vastlopen.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
Ontkoppel de generatie van lengtebeperkingen.
Van toepassing op: Prompt API, aangezien dit de enige API is die gestructureerde uitvoerschema's ondersteunt.
Doe: Laat het model op natuurlijke wijze een reactie genereren en gebruik vervolgens client-side logica om de tekst in te korten zodat deze in je gebruikersinterface past.
Niet doen: Strikte tekenlimieten zoals maxLength: 125 afdwingen met behulp van gestructureerde uitvoerschema's . Wanneer het antwoord van een model langer is dan de ingestelde limiet, kan het model overschakelen naar tokens met een hoge dichtheid, zoals vreemde talen of emoji, om de betekenis te comprimeren, wat resulteert in onzinnige uitvoer.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
Houd de gebruiker op de hoogte.
Van toepassing op: Alle API's.
Doe: Afhankelijk van de complexiteit en de verwachte duur van de taak, gebruik animaties, visuele aanwijzingen en voortgangsindicatoren om de gebruiker op de hoogte te houden. De optimale aanpak hangt af van uw specifieke gebruikssituatie en de verwachte lengte van de API-output. Enkele ideeën:
- Streaming voor lange content: Voor samenvattingen of chatberichten creëert streaming standaard een typemachine-effect per token. Dit kan natuurlijk aanvoelen en direct feedback geven.
- Niet-streaming voor korte taken (of lange asynchrone taken): Voor korte outputs, bijvoorbeeld alt-tekst, kan niet-streaming een meer verfijnde gebruikersinterface opleveren. Het geeft ook de tijd om de volgende AI-taak voor te bereiden terwijl de huidige taak wordt uitgevoerd. Deze aanpak werkt ook voor langere asynchrone of achtergrondtaken. Als de gebruiker niet wordt geblokkeerd door de output en zijn of haar reis kan vervolgen, is er geen dringende noodzaak om de output direct te produceren. Geef in de gebruikersinterface aan dat het proces nog gaande is.
- Visuele overgangen voor updates: Gebruik animaties, bijvoorbeeld woordvervorming, bij het vertalen of herschrijven van tekst.
Niet doen: De gebruikersinterface bijwerken zonder visuele aanwijzingen.
Sluit aan bij het mentale model van tijd en werk van de gebruiker.
Van toepassing op: Alle API's.
Doe: Overweeg een kunstmatige vertraging van één of twee seconden als een reactie bijna direct is. Paradoxaal genoeg vinden gebruikers de resultaten mogelijk betrouwbaarder wanneer ze een generatieproces waarnemen dat aansluit bij de door hen ervaren moeilijkheidsgraad van de taak. Gebruik animaties om aan te geven dat er een AI-proces heeft plaatsgevonden.
Niet doen: gebruikers verrassen met plotselinge vervangingen van de gebruikersinterface.
Geef gebruikers de mogelijkheid om snel door AI-bewerkingen te navigeren en deze ongedaan te maken.
Van toepassing op: Alle API's.
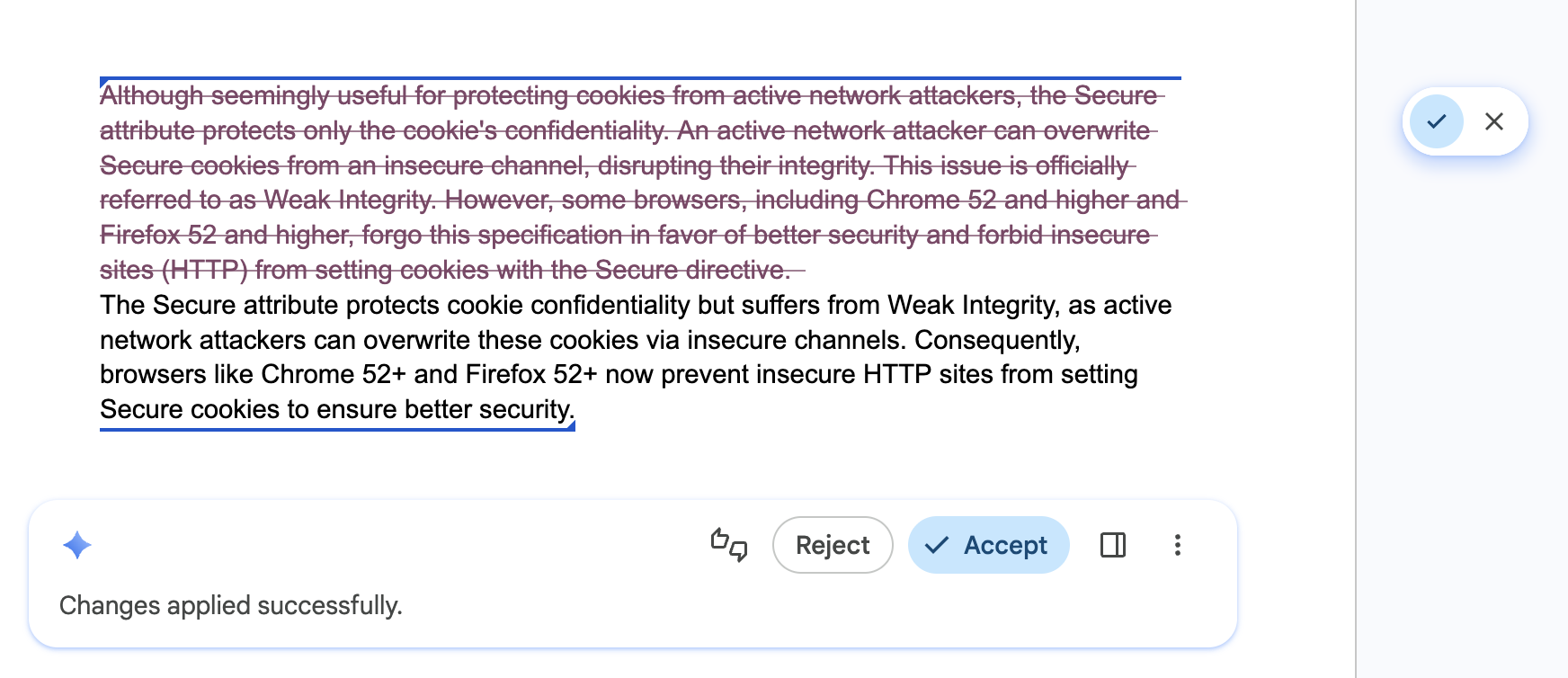
Doe: Voorzie je gebruikersinterface van een stappenplan of navigatiegeschiedenis waarmee gebruikers verschillende resultaten vol vertrouwen kunnen bekijken en AI-bewerkingen snel ongedaan kunnen maken. Zo blijven verschillende versies altijd beschikbaar.
Niet doen: De vorige versie van de gebruiker overschrijven, of een AI-resultaat dat de gebruiker wellicht beviel, zonder de mogelijkheid om terug te gaan, de wijzigingen ongedaan te maken of versies te vergelijken.
Geef gebruikers controle en de mogelijkheid om wijzigingen te overschrijven.
Van toepassing op: Alle API's.
Te doen: Maak de gebruiker de eindredacteur van alle gegenereerde content. Bied intuïtieve opties om de uitvoer te overschrijven, zodat de gebruiker de volledige controle over het eindresultaat behoudt. De API's kunnen onjuiste resultaten opleveren.
Niet doen: Een door AI gegenereerd resultaat als enige optie opleggen.
Cache de resultaten voor herhaalde taken.
Van toepassing op: Alle API's.
Doe het volgende: Implementeer een lokale resultaatcache (bijvoorbeeld met sessionStorage of IndexedDB ) voor herhaalde invoer of query's. Normaliseer de invoer door witruimte te verwijderen en kleine letters toe te voegen om het aantal cachehits te verhogen. Genereer voor grote hoeveelheden invoer, zoals afbeeldingen, een hash die als cachesleutel kan worden gebruikt. Stel een conservatieve time-to-live (TTL) in voor uw cache (of serveer gecachede resultaten terwijl u ze op de achtergrond bijwerkt). Laat de gebruiker een nieuwe inferentie starten als het resultaat niet bevredigend is.
Niet doen: Dezelfde inferentie opnieuw uitvoeren voor een herhaalde zoekopdracht of identieke gegevensinvoer waarbij variabiliteit niet wenselijk is, bijvoorbeeld wanneer een gebruiker heen en weer navigeert tussen zoekresultaten. Dit optimaliseert de responsiviteit en het efficiënte gebruik van de lokale rekenkracht.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}