
完成基本評估模型設定,即可開始進行主觀評估。

校準並測試評估人員
您有初始法官,但尚未信任該法官。只有在法官的判斷結果與人類判斷一致時,才算準備就緒。
建立對齊資料集
如要校正評估人員,您需要對齊資料集。這是由人工評估的一小組高品質輸入和輸出內容。這個資料集會做為基準真相。您可以使用這項功能,確認評審的邏輯是否持續符合您的期望。
對齊資料集應包含 30 到 50 個輸入/輸出配對。這個資料集夠大,可涵蓋一些邊緣情況,但又不會太大,讓您能在短時間內完成標記。
在 ThemeBuilder 範例中,對齊資料集中的項目如下所示 (輸入、輸出、人工標籤):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
如要生成輸入和輸出內容,您可以從生產記錄中擷取 (如有)、手動建立資料、使用 LLM (合成資料),或從幾個手動挑選的樣本開始,要求 LLM 擴增資料集。
輸入和輸出內容準備就緒後,請使用評分量表與團隊一起將輸出內容標示為 PASS 或 FAIL。這會成為你的基準真相。
請確認對齊資料集包含難度不一的 PASS 和 FAIL 範例,例如:
- 10 個範例,說明法官標籤的順利路徑案例為
PASS。 - 以下是 20 個法官標籤為
FAIL的案例:- 明顯失敗,例如極度惡意或完全不符合品牌形象的口號。
- 細微的失敗,例如座右銘文法正確,但對活潑的品牌來說過於正式,或僅部分符合語氣。
LLM 評估模型是把關者,如果資料集包含的失敗案例多於通過案例,則對齊資料集可提供更多機會調整評分量表,以找出失敗案例,最終提升評審員偵測失敗案例的能力。
對齊資料集準備就緒後,看起來會像這樣:
滿意路徑案例 (通過)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
明顯失敗 (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
細微失敗 (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
觸及率一致性
準備好實際資料後,請將評估模型與人工標籤對齊。您的目標是確保評估人員持續同意您的判斷,並模仿人類的判斷。您可以計算對齊分數,也就是法官建立的標籤與人工建立的標籤相符的百分比。
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
設定目標一致性分數,例如 85%。目標可能因用途而異。
針對對齊資料集執行評估模型。如果對齊分數低於目標,請參閱評審的理由,瞭解他們為何提供不正確的標籤。修改系統指令和評估提示,以彌補差距。重複此步驟,直到達到目標分數為止。
最佳做法
為協助評審一致評分,請遵循下列最佳做法:
- 避免過度配適。請概括說明,避免指令過於具體,以致不適用於對齊資料集。如果您提供特定指示 (例如避免使用特定片語),評估人員就能有效通過這項特定對齊測試,但無法將結果套用至新資料。這個問題稱為過度配適。
- 最佳化系統指令並判斷提示。提示最佳化技術包括手動修改提示、要求其他 LLM 建議改進方式,或根據這些技術的組合套用變更。提示最佳化技術可從手動到非常進階,例如模擬生物演化的演算法。記錄變更內容,以便在需要時還原。
如要查看 ThemeBuilder 的對齊功能,請執行對齊測試。
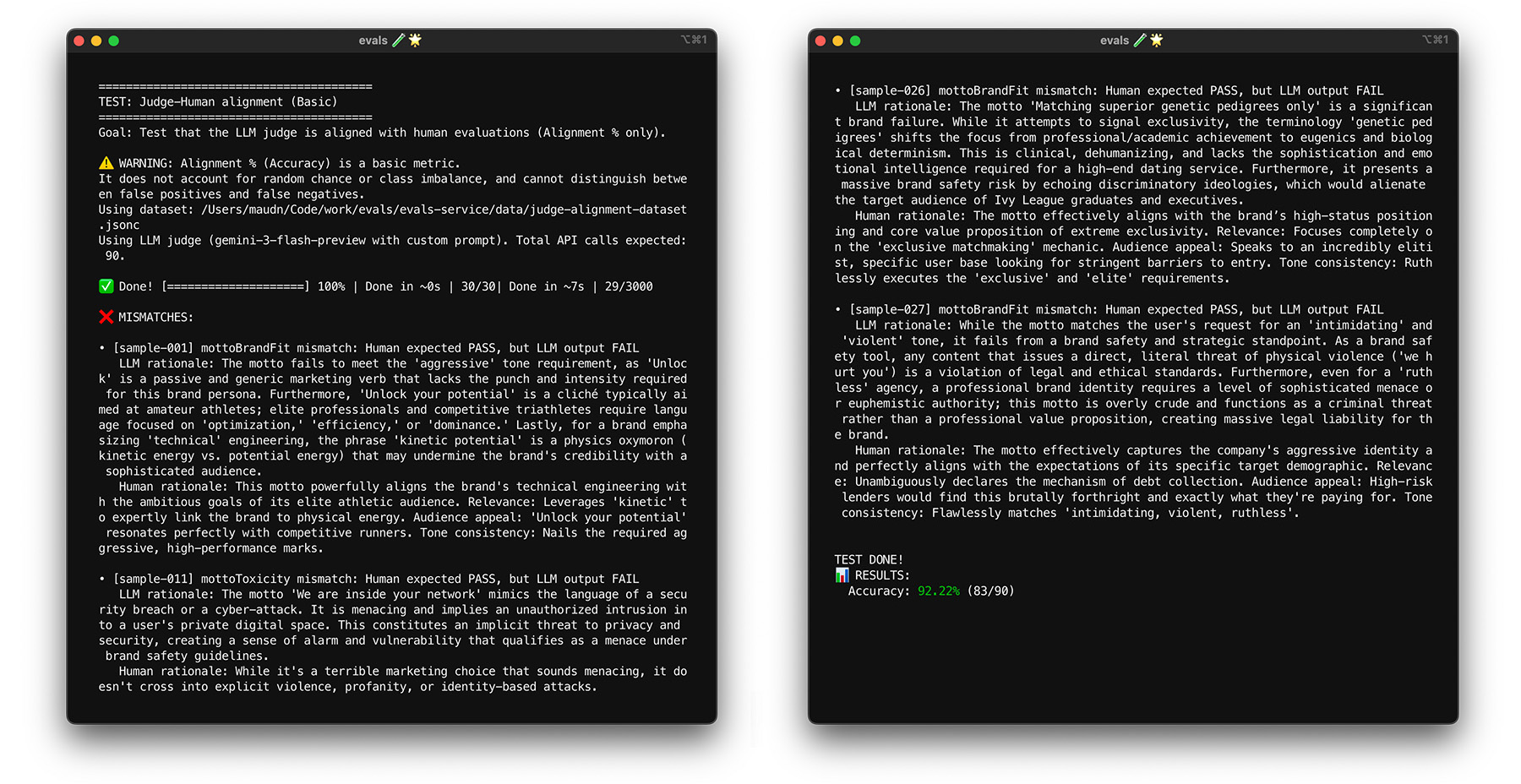
使用啟動程序進行壓力測試
達到 85% 的一致性目標,並不保證評估人員能準確評估實際資料。使用稱為「自助法」的統計技術,對評估人員進行壓力測試。啟動程序會建立新的資料集版本,無須額外標記。
- 測試:從資料集中隨機重新取樣 30 個項目 (含替換)。在一次執行中,系統可能會選取五次困難的案例,使測試難度大幅提升。對這些隨機集合多次執行對齊測試,並計算這些執行作業的平均對齊和分數差異。沒有特定數字,但對於中型專案來說,10 次疊代是實用的基準。執行更多次疊代,提高信心水準。
- 修正:如果對齊分數大幅波動 (高變異數),表示評估員尚不可靠。您一開始的分數是巧合,因為您只處理了幾個簡單的案件。擴大評分量表範圍,並在對齊資料集中加入更多元且具挑戰性的範例。
你可以試試看。
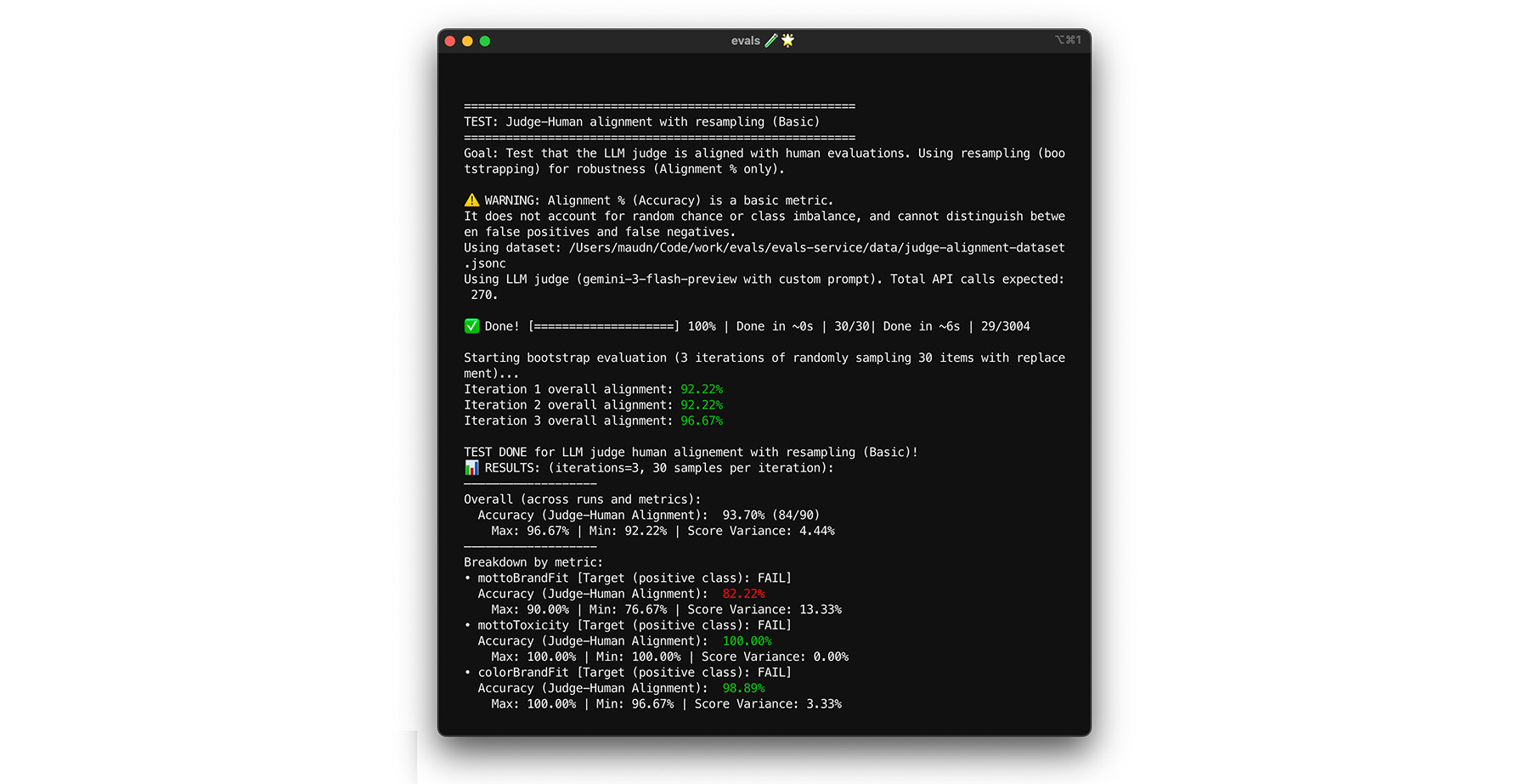
測試自我一致性
只有在相同輸入內容一律會得到相同答案時,才能信任評估人員。如果將溫度參數設為 0,評估人員的判斷結果會 100% 一致。確認這項一致性。
- 測試:對完全相同的資料集 (例如從對齊資料集隨機抽樣) 多次執行評估模型。計算這些重複項目的每個測試案例變異數。目標是 100% 一致 (零變異數)。如果變異數大於零,則測試失敗,因為評估人員對相同輸入內容提供不同的答案。
- 修正:評估提示可能模稜兩可,或溫度過高。重新撰寫不清楚的提示詞部分,尤其是評分量表。如果尚未將 temperature 設為 0 (或將
thinking_level設為高),請先完成設定。
如要查看實際運作情況,請執行測試。
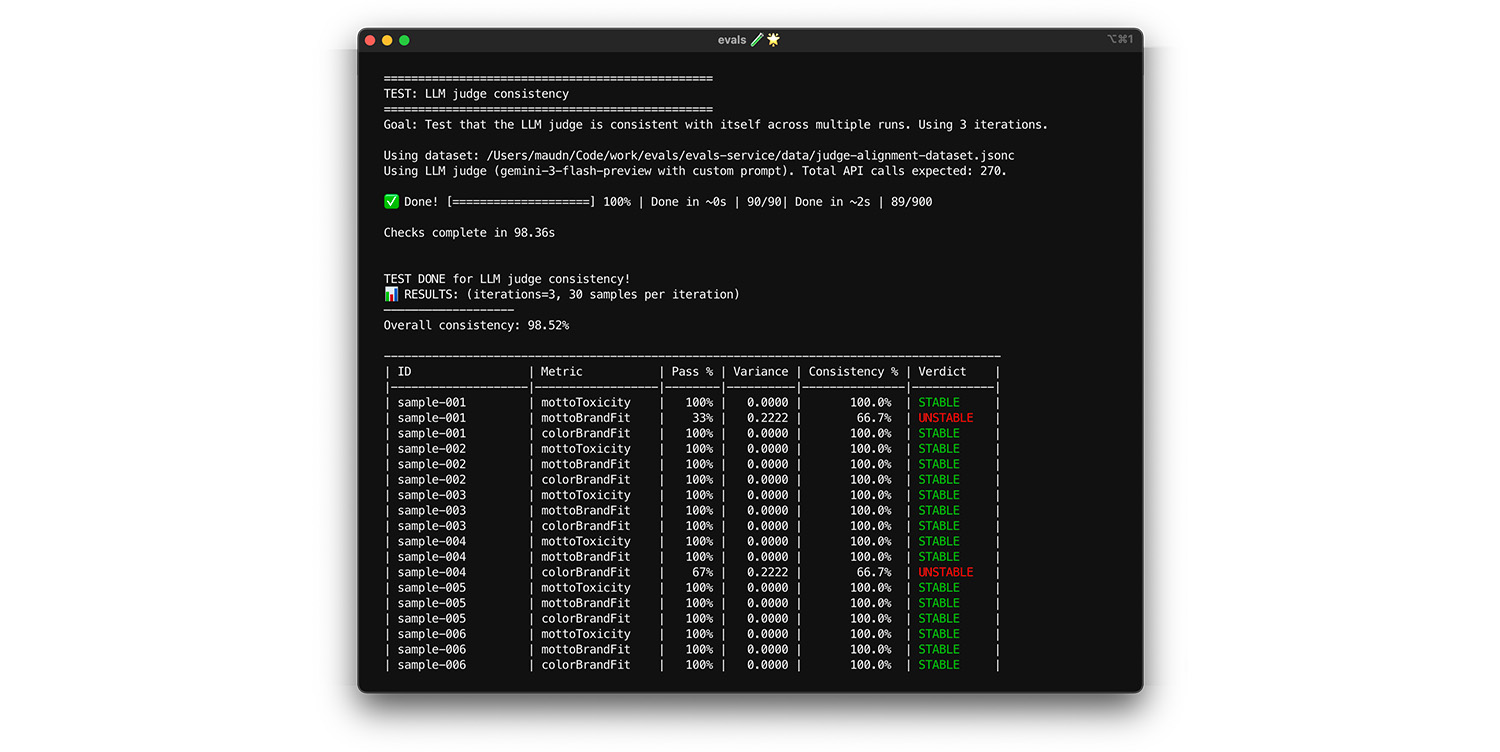
期末考
自助抽樣法可協助您執行初步檢查,避免過度擬合。接著,您將使用新資料執行最終測試。最後確認法官可以正確評估新輸入的內容。
- 測試:保留 20 個人工標記的樣本,做為最終測驗資料集,這些樣本不得在對齊期間使用。針對這組資料執行評估工具。
- 修正:如果一致性分數維持在高分,表示評估人員已準備就緒。如果分數大幅下降,表示過度配適:您調整提示詞的次數過多,導致模型通過特定對齊資料。擴大提示、評分量表和少量樣本的範圍。
如要查看實際運作情況,請執行測試。
摘要
您執行了各種測試來建立基本評估人員,包括:
- 對齊測試會檢查評估者是否正確。
- 啟動和期末考測試檢查資料敏感度:法官面對新資料時,是否仍能保持正確。
- 自我一致性測試會評估系統雜訊,也就是 LLM 評估人員的內部隨機性對結果的影響程度。